财税版DeepResearch的构建实践
前言

马拉火车做为开篇大图,以启发读者和笔者的思考。
Agent架构设计
在过去的一段时间,业界对于agent几乎从未形成一个定义。从技术实现的角度来看,Agent是LLM is in a loop.虽然如此,从Lilian Weng的blog中的这张图开始,多数情况下还是能够形成些许共识。

Agent设计模式
Antonio Gulli(Google Cloud, CTO)的新书《Agentic Design Patterns: A Hands-On Guide to Building Intelligent Systems》中对智能体设计模式做了整体梳理,如下所示。
提示链
提示链是通过提示词构建一个pipeline进行任务处理。本质上是workflow的范畴,不过在pipeline的各个环节是通过提示词实现的。优点是可控,独立优化和部署,缺点是存在错误传递的可能。也是比较常用的一种设计模式。
路由
通过路由层实现意图分发,分发至子智能体,工具链,人工(追问&拒识)。具体的实现方式可以是大模型,向量,规则和传统机器学习模型。
并行
通过异步通信,多线程和多进程的方式,将构建的agent进行架构调优,实现并行化,减少总体等待时间。
反思
引入反思模式可以构建包含反馈循环的智能体工作流。实现方式包括通过单个智能体,或者两个智能体。通常后者通过职责分离模式,能够产生更稳健,更客观的结果。
工具使用
function calling的能力是连接大模型的推理能力和外部工具的技术桥梁。通过需要工具定义,工具调度,工具执行,工具结果获取和反馈。其中工具的类型包括外部API,数据库访问,服务交互,代码执行,搜索工具等。
常用的工具包括命令执行(含Python执行),文件读写,搜索,浏览器,已经能够覆盖绝大多数场景,网传Manus的工具有29种。
规划
规划是指在完成一个目标的时候,根据目标进行执行步骤的拆解,形成一个执行计划。比如大模型的Think模式,显式的任务安排(旅行计划),DeepResearch,Claude Code的执行计划,Manus作为通用智能体的TODO设计等。
通过规划,可以实现大模型推理过程的显性化,必要的时候可以引入人类参与的干预。同时也提供了一种模型完成任务时的工作流拆解方式,且这种拆解是模型自发的行为。因此,对模型和人,都是一个比较好的设计模式。
多智能体协作
多智能体是一种通用的设计模式,基于任务分解原则,可以将高层目标拆解为多个子问题,每个子问题可以有各自的智能体进行问题解决。本质是一种群体智能的实现方式,相比单体架构,在模块化,可扩展性和鲁棒性上表现的更好。
协作的方式包括但不限于顺序交接,并行处理,辩论和共识,层级结构(类比管理结构),专家团队和评审者模式。
记忆
记忆分为短期记忆和长期记忆。在AI记忆系统的技术演进与设计哲学中有更详细的描述。
MCP
一种通用连接机制,建立大模型和周围环境的标准通信协议。可以认为是工具函数调用能力的进一步标准化。
目标设定和监控
针对目标实现过程的监控,并根据监控进行反馈的模式。
人机协同
必要的时候,决策交给人类。
RAG
获取实时,可验证的数据上。
A2A
MCP侧重于智能体和外部数据以及工具的交互,A2A侧重于智能体之间的协调和通信。涉及的交互机制包括同步请求/响应,异步轮询,流式更新和推送通知。
资源感知优化
系统在设计过程中关注计算,时间和财务资源。比如大小模型的融合,超过资源预算自动终止,时间优先或者效果优先等
推理技术
包括CoT,ReAct,DeepResearch等。在书中的第17章给了相对全面的描述。
评估和监控
智能体系统的可观测性实现。
优先级排序
包括智能体运行过程中的目标排序,动作排序等。
探索和发现
并非所有的解决方案都是可以预定义的,该模式允许智能体系统能够主动寻找新的信息,发现新的可能性。典型的应用场景如科学研究。在OpenAI定义的5层AI水平分类中,居于Agent之上的层次。
财税版DeepResearch
技术方案
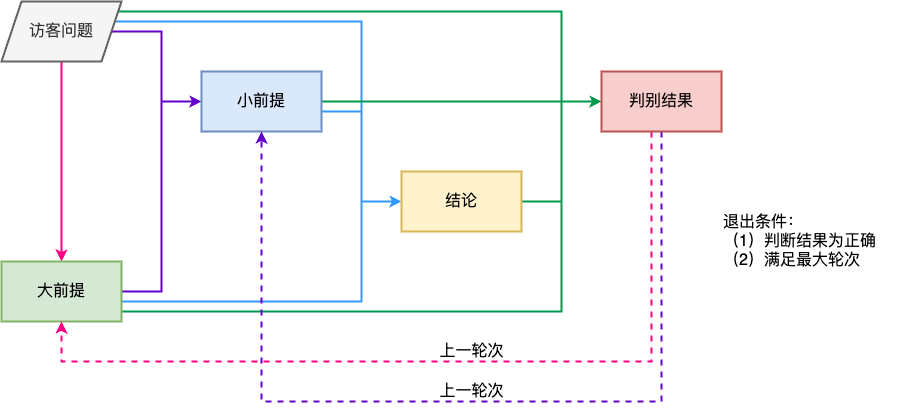
针对财税实务咨询中的问题,也许可以参考法律中的三段论思想进行解决,相关工作在法律领域已经有诸多的实践。恰逢做这个工作的时候,tongyi-deep-research模型发布,文章中称效果比OpenAI的deepresearch要好。
deepresearch的架构包含四种,分别是中心式的架构,pipeline的架构,multi-agent的架构以及混合架构。tongyi-deep-research是基于一个中心化的agentic模型实现全流程的自主运行。基于财税领域的具体问题适配之后的架构如下:
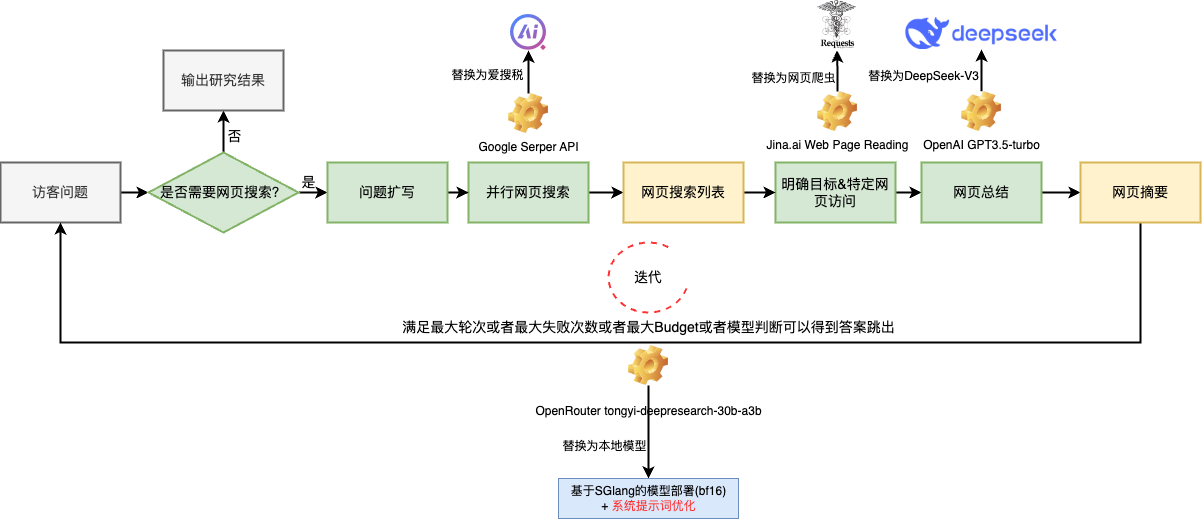
考虑到可控性,在快速尝试了上述实现方式之后,构建了一个pipeline的架构,如下:
实测后者的效果显著优于前者。
反思
现实的构建途径如下:
(1)agentic model
(2)基于ReAct的多个提示词
(3)考虑multi-agent。将裁判器做为一个独立的agent
(4)不考虑微调
理想的构建途径如下:
(1)单个提示词执行三段论
(2)基于ReAct的多个提示词
(3)multi-agent
(4)部分环节对应模块的微调
经验总结
结合《如何让Agent更符合预期?》以及自身构建Agent的经验进行讨论如下。
- 预期清晰化
没有清晰的预期,写不出清晰的指令,更没有清晰的衡量标准。其中的难点是在财税垂直领域,存在有些预期是无法准确并清晰化的描述的,同时需要清晰化描述的概念过多。一种解决方案是能够描述的尽可能描述,另外一种方案是通过搜索的方案绕过需要描述的情况。
- 上下文精准化
只给模型需要的上下文,不能少给,也不能多给。其中的问题在于:部分情况下,是无法知道模型需要什么样的上下文。如果少给,会寄希望于模型内部能够补全缺失的上下文;如果多给,寄希望于模型能够通过自动化的筛选,选择必要的上下文内容。
精准化的本质是通过人类完成对上下文的预处理。这里有较多非常实用的技术:context offloading/reducing context(可逆的压缩和不可逆的总结)/retrieving context/context isolation/caching context等
- 三方角色不清晰导致模型错乱
避免轻易删除或者篡改模型完整的探索历史,包括未被采纳的错误常识。在AI Coding工具的产品设计中,会保留一个对话的tag作为模型的记忆,记忆的问题在笔者的关于最后一句抽取的文章中也有探讨,并非轻易作出选择。如果可能的话,尽可能保留完整对话上下文,同时对角色有所清晰的区分和标识。
- 采用形式化的表达逻辑
在提示词中,采用形式化的表达逻辑,更加严密且适合模型去理解。比如用json形式表达一个流程步骤的处理逻辑。在要素抽取这个任务中,提示词中描述了很多if…then…的逻辑,相比采用自然语言的表达方式,直接采用if…then…的表达效果更好。
- 自定义工具协议
在作者的实践中,发现自定义的工具协议效果优于标准协议,给了一个基本的猜测如下:
模型在为通用协议进行训练时,其思考和调用逻辑相对收到了训练数据的影响和固化。当你的领域化需求遇上它的内在逻辑时,它会默认按照训练语料中的方式去理解和调用,所以不会完全遵循你的指令。
- 成也few-shot,败也few-shot
单任务中善用few-shot,灵活的任务中慎用few-shot。在财税垂直领域的对话系统构建中,由于场景的灵活性,few-shot多数情况下没有发挥对应的价值。
- 记忆管理避免模型遗忘
典型的方式包括重点信息增强提示,上下文压缩和外存。在笔者遇到的一个录音对话数据挖掘中,单个录音对话2个小时左右,大几万字的文本数据,在进行对话挖掘的时候,势必要进行长文本的处理。
- multi-agent实现可控性和灵活性
主agent进行调度决策,子agent进行固定,复杂流程的workflow的执行(比如规则引擎或者单个LLM)。类比,在大模型对话中,通过think进行planning,调用工具执行确定的动作,比如search等。
- 人机结合
没有人是万万不行的。
个人思考
- 智能体系统的构建需要在算法,工程和数据之间进行良好的架构设计(关注架构)
算法侧关心效果和速度,且效果>速度;工程侧关心任务完成率,要容错性高,稳定性好,同时吞吐能力强;针对系统运行过程中的数据,必要时具备海量数据处理的能力(Manus的海量数据处理场景)。
- 为什么一定要做Agent?
提供了一种更加抽象和通用的系统构建方式,是生产工具的飞跃,带来了生产力的巨大提升。
- 重组
在前老板写的文章《基于多Agent架构的新一代智能助理:重塑医疗信息化的“超级大脑”》中,可以看到AI如何和传统的业务中台和数据中台进行多方联动。在LLM之前,虽然我们也在讨论同样的问题,但是LLM之后,通过重组使得理想越来越接近现实。
相关资料
文章中作者的思想是马拉火车是暂时的,火车最终还是会自己跑,同样长途走路,只是我们不再需要马车,而是火车。
和claude code的产品设计哲学有一致之处,cli+code是天作之合。
Manus团队的前同学写的文章,描绘了一个比较大的Agent逻辑。
给了很多关于context管理的具体技术建议。比较印象深刻的结论:相信模型的能力,不要过度的工程化。
扫码加笔者好友,茶已备好,等你来聊~