财税垂域模型微调的数据合成方法预研
前言
在《On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey》中,将数据合成分为三个阶段,分别是Generation->Curation->Evaluation。笔者最近参与一个模型微调的事情,故在这里梳理一下可能的数据合成方法。
由于财税是一个垂直专业领域,同时是强知识依赖的,所以knowledge grounded是一件非常重要的事情。其中knowledge的形式可以是非结构化的文本,也可以是结构化的知识图谱等。
《Fin-R1: A Large Language Model for Financial Reasoning through Reinforcement Learning》
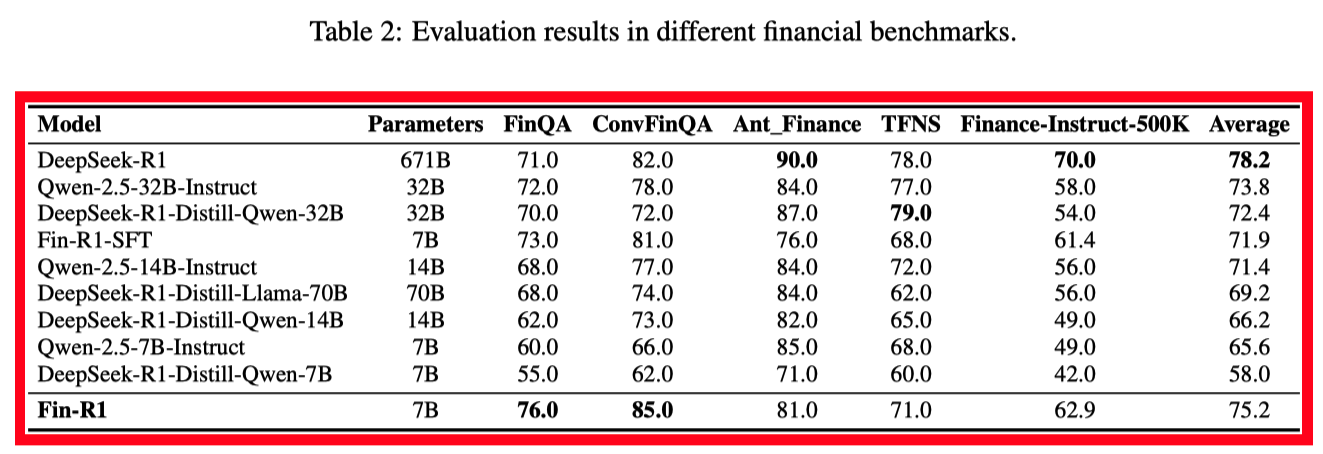
该工作是上海财经大学和财跃星辰共同完成,Fin-R1的数据构建思路是基于学术多项选择题,采用蒸馏DeepSeek-R1,对生成的思考过程和答案进行双重校验。
基于构建的数据, 经过sft+rl的7B的模型在效果上优于70B的模型,不过最终效果还是距离DeepSeek-R1有较远的距离。具体实验结果如下所示:
《ReasonMed-A 370K Multi-Agent Generated Dataset for Advancing Medical Reasoning》
这篇文章是EMNLP2025的高分文章,主要内容是构建了一个ReasonMed的大规模数据集。相比上边的工作,ReasonMed的数据集的构建流程更加地细致,也就是数据curation的过程更加地精细。
基于7B模型的sft的微调,效果优于70B的模型,并没有rl的过程。
夸克健康大模型
夸克健康大模型的数据处理流程如下所示:

主要分为以下几个阶段,分别如下:
(1) 数据采样阶段。采集线上搜索日志中的query。
(2) 医疗知识grounded生成。根据采样的query,获取搜索引擎返回的相关搜索结果。
(3) 候选答案生成。
(4) 人类专家的数据验证。
(5) 基于规则的数据标注。对于人类专家的结果,利用规则进行验证。
Baichuan-M2
Baichuan-M2的整体训练流程分为三个阶段,分别是mid-training,supervised fine-tuning和reinforcement learning, 具体如下所示:
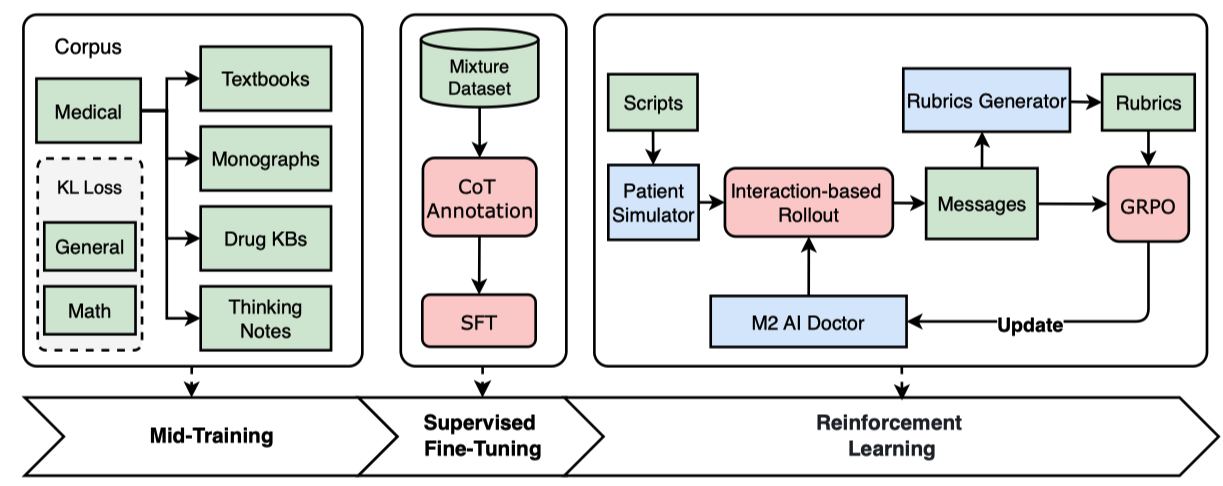
亮点在于verifier系统的构建,如下:
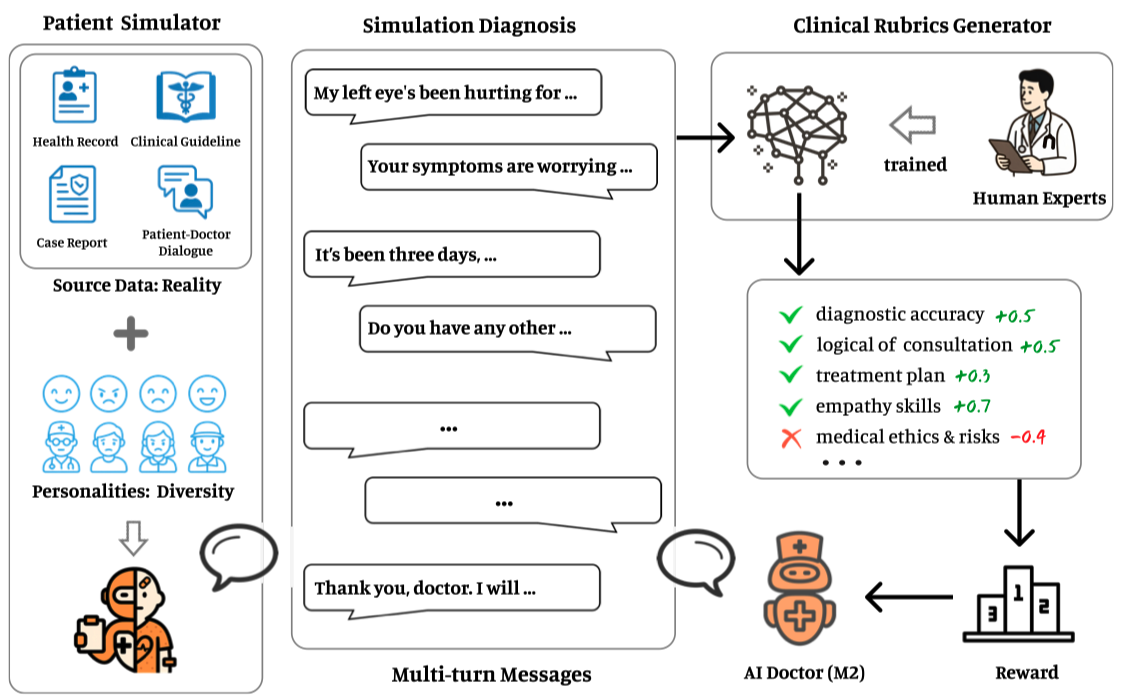
通过患者模拟器,可以动态持续地生成对话数据,通过clinical rubrics generator,可以动态持续地对对话进行打分形成reward,由此形成了一个闭环系统。
在财税咨询对话系统中,如果只用海量的真实咨询对话数据去构建类似的系统,是否可以work?答案也许是否定的。财税对话系统中存在知识依赖和推理依赖,如果没有将二者以显性的方式告诉模型,除非模型自身具备垂直知识和相关推理能力(无法验证),否则模型大概率无法学到正确的咨询能力。
但是通过将对话生产的过程实现自主可控,就可以在构建对话的时候,实现知识和能力的即时注入。
在Baichuan-M2 plus中,提出知识侧的“六源”,自底向上分别是研究(事实是否存在?),综述(结论是否一致?),指南(行业如何规范?),实践(医生如何决策?),教育(患者如何理解?)和反馈(是否存在新的风险?)。检索侧采用PICO框架,在“六源”中进行分层检索。最后利用模型的能力实现循证推理,特色能力包括如下:
(1) 奖励引用,惩罚臆测
(2) 内置证据评估器,嵌入在推理链中
(3) 句句有据,可回溯,可验证
基于Baichuan-M2,plus的到底是什么?笔者理解包括如下:
(1)六源知识体系的搭建。无论是模型还是应用都会有所依赖
(2)RL阶段引入上述(2)和(3)特性的reward
(3)PICO以及检索的引入
tongyi-deepresearch的数据合成方法

mid training的两个重要操作:
(1)32K->128K的两阶段训练。通过这种方式可以强化模型的coherent,long-horizon reasoning和action的能力
(2)训练时增加小比例的通用预训练数据,保证模型在获取专用的agentic能力的同时,不牺牲基础通用能力
该阶段的数据合成流程如下:
post training阶段主要包括数据合成,监督微调用于冷启动,agentic RL。
其中数据合成的方法依赖如下:
The process begins by constructing a highly interconnected knowledge graph via random walks, leveraging web search to acquire relevant knowledge, and isomorphic tables from real-world websites, ensuring a realistic information structure.
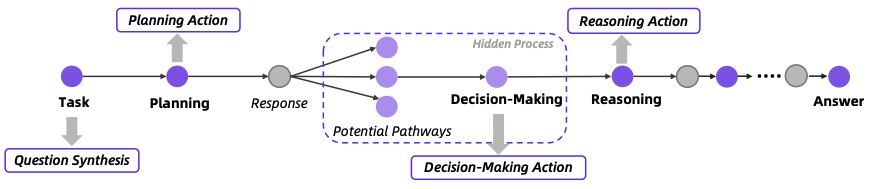
完整的agentic RL框架如下所示:
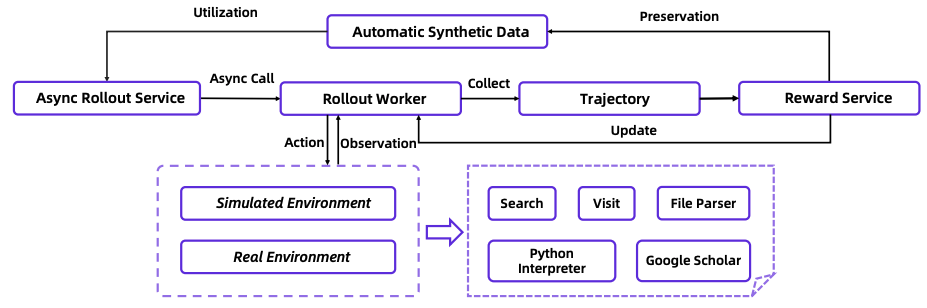
这个图大概率是一个工程能力挺好的同学画的。😊
个人思考
监督学习场景下,模型训练的过程是引入bias的过程,而数据是bias的来源。在knowledge grounded场景中,由于knowledge的来源和种类非常多,因此如何利用knowledge进行数据合成就是一个重要的问题。
知识密集型垂域,几乎所有的挑战都会收敛到:需要知识吗?知识是什么?知识怎么组织?知识怎么利用?
sft范式下,data决定了模型的上限;rl的范式下,似乎有更大的想象力空间。
笔者问DeepSeek,“从控制论和信息论角度解释数据合成的必要性?”,DeepSeek给出的回答如下,以飨读者。
将两者结合,我们可以得到一个统一的图景:从“知”(信息论)的角度,数据合成是为了对抗信息熵,用先验知识填补认知空白,为模型提供更丰富、更纯净的信息源,使其能够学习到数据本质的、泛化的规律,从而降低在未知世界中的不确定性。从“行”(控制论)的角度,数据合成是为了主动构建一个具有足够多样性的训练环境,使模型(控制器)能够具备应对真实世界复杂性和长尾案例的必要能力,并能够在安全、高效的环境中通过模拟和预测来优化其行为策略。因此,数据合成远非简单的数据扩充技巧,而是在信息受限和环境复杂的双重约束下,使人工智能系统能够有效“认知”和“行动”的核心工程哲学与必要技术手段。
相关资料
(1)《Tongyi DeepResearch Technical Report》
(2)《On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey》
扫码加笔者好友,茶已备好,等你来聊~