再议agent中的memory
前言:在前一篇博客,《AI记忆系统的技术演进与设计哲学》中,笔者梳理了chatgpt,claude和manus等大产品中的memory工程设计并进行了部分对比,整体的粒度较粗,这篇博客中笔者从更细的粒度中梳理近期围绕agent的memory工程相关的工作。
Memory的概念体系
围绕memory的认知模型早在1983年就由三位大佬提出,在今天讨论memory的时候,并没有脱离具体的认知模型,但是具体的实现方式发生了变化。整体框架如下所示:
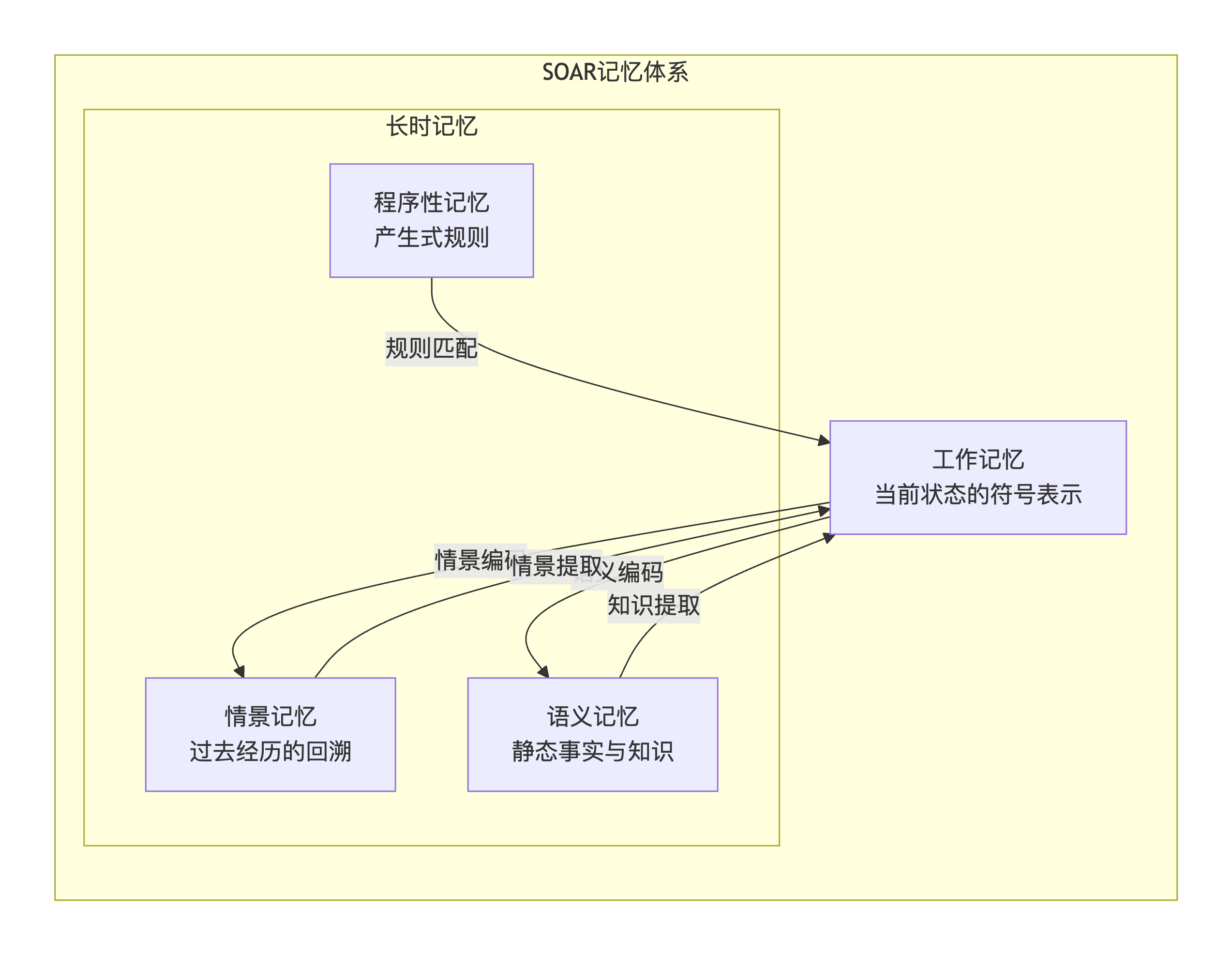
结合大模型的技术体系,笔者根据多个学术和工业界的工作,梳理了更加具体的memory的概念体系,具体如下:
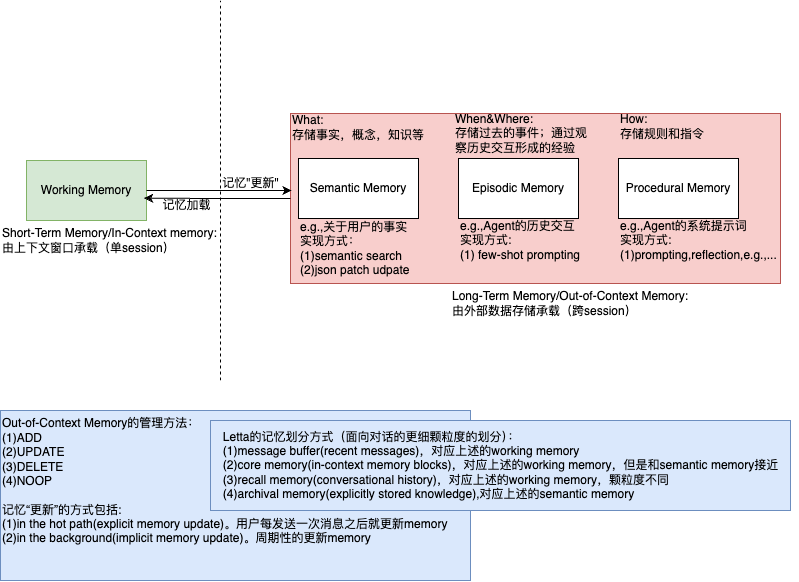
在技术实现这个维度上,通过memory的方式,建立针对memory的encode,storage和retrieval(《Rethinking Memory in AI: Taxonomy, Operations, Topics, and Future Directions》中提供了更多的关于memory的操作),将agent从stateless变为stateful,其实并没有脱离更好的context engineering这个范畴。
在《From Human Memory to AI Memory-A Survey on Memory Mechanisms in the Era of LLMs》中进行AI和人类记忆的对比的时候,增加了sensory memory类型。
重点工作梳理
MIRIX: Multi-Agent Memory System for LLM-Based Agents,该工作中首先对记忆进行了分模块,同时提出了一个架构方式(偏工程体系搭建),最后基于一套算法和工程体系构建了应用,宣称世界上最强的用于agent的记忆系统。具体的模块划分方式如下所示:
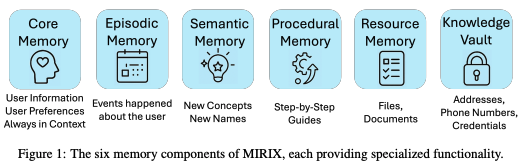
围绕memory的认知架构是基于soar,技术架构是multi-agent的,针对memory的agent是通过提示词的方案来实现的,具体见代码,类似的实现见这里,提供了一个非常简单的POC。使用方式如下:
# Original code:
# response = agent.query(message)
from mirix import MemoryClient
client = MemoryClient(local=True)
# 1. Inject relevant context into the prompt
message = client.wrap_message(message)
response = agent.query(message)
# 2. Save the interaction
client.add(messages=[
{"role": "user", "content": [{"type": "text", "text": message}]},
{"role": "assistant", "content": [{"type": "text", "text": response}]}
])
MemOS: A Memory OS for AI System,这篇的工作同上基本类似,也做了一个应用。从工程侧包括对记忆生产,记忆调度和记忆召回以及记忆生命周期管理。其中记忆类型可划分为以下:
- KV Cache记忆-适合常见问题以及特定领域知识,和先前的对话历史
- 明文记忆
- 通用明文记忆-通过向量检索等方式进行搜索
- 树形明文记忆-基于图的记忆管理
- Neo4j图数据库
- Nebula图数据库
- 参数记忆-模型训练参数(预训练权重和模块化的权重组件,如LoRA适配器和专家模块),实现记忆的动态加载和卸载
这个工作中对于memory的定义比sora更加广泛,比如认为kv cache和model parameter均是记忆的一种类型,同时在范式上抽象了MemCube,以及MOS(Memory Operating System),MAG(Memory Augmented Generation)等概念,比如MOS的使用方式如下所示:
from memos.configs.mem_os import MOSConfig
from memos.mem_os.main import MOS
# init MOS
mos_config = MOSConfig.from_json_file("examples/data/config/simple_memos_config.json")
memory = MOS(mos_config)
# create user
user_id = "b41a34d5-5cae-4b46-8c49-d03794d206f5"
memory.create_user(user_id=user_id)
# register cube for user
memory.register_mem_cube("examples/data/mem_cube_2", user_id=user_id)
# add memory for user
memory.add(
messages=[
{"role": "user", "content": "I like playing football."},
{"role": "assistant", "content": "I like playing football too."},
],
user_id=user_id,
)
# Later, when you want to retrieve memory for user
retrieved_memories = memory.search(query="What do you like?", user_id=user_id)
# output text_memories: I like playing football, act_memories, para_memories
print(f"text_memories: {retrieved_memories['text_mem']}")
The Evolution from RAG to Agentic RAG to Agent, 这篇博客对RAG系统的演进历史进行了梳理,RAG(Read-Only, One-Shot)->Agentic RAG(Smart Read-Only)->Agent Memory(Read-Write Operations)。同时和其他工作类型,对记忆进行了类型划分:
- procedural. For example, use emojis
- episodic. For example, use mentioned trip on Oct 30
- semantic. For example, Eiffel Tower is 330m tall
具体对比如下:
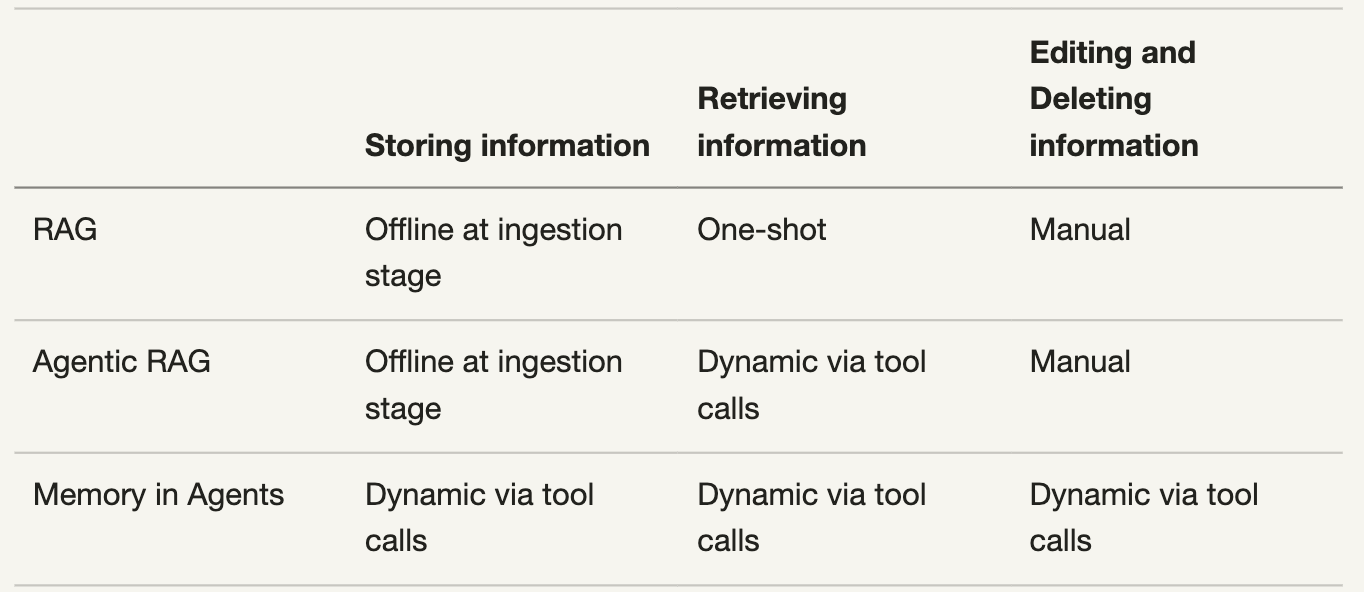
简单而言,针对记忆的处理,需要有write的能力。
《MemGPT: Towards LLMs as Operating Systems》,在letta(也是一家关于memory的创业公司)的blog中针对该工作进行了实现,该工作的核心是两个部分分别如下:
- 一个两层memory架构。main context(in-context)+external context(out-of-context)
- self-editing memory capabilities through tool use,MIRIX中也是通过function call的能力进行memory的管理
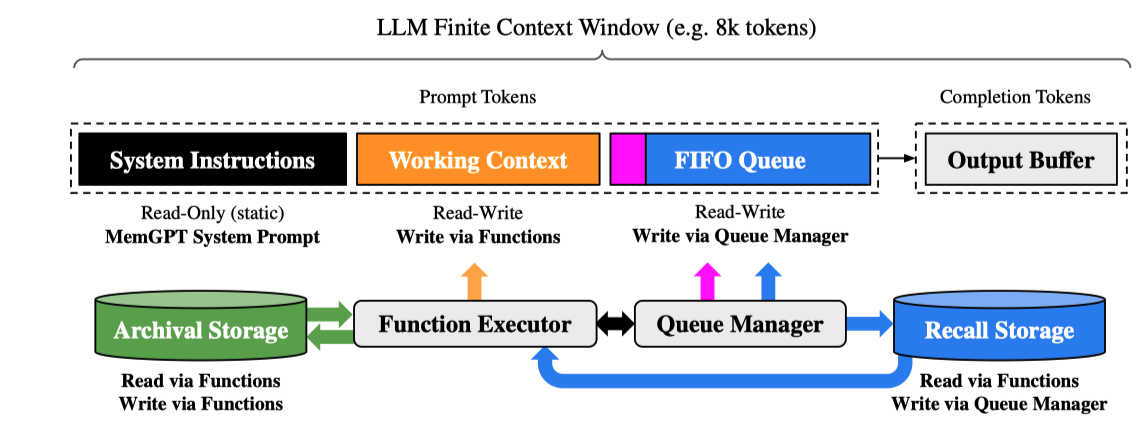
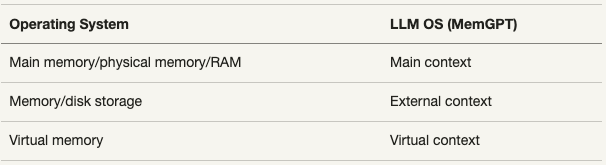
在letta的工作中,做了LLM OS和传统OS的一个对比,结果如下:
具体实现依然是基于prompt的艺术,代码见这里,竟然发现MIRIX的prompts和letta的prompts几乎是一模一样,没有仔细看协议,也许是允许的。使用体验上和上述差不多。
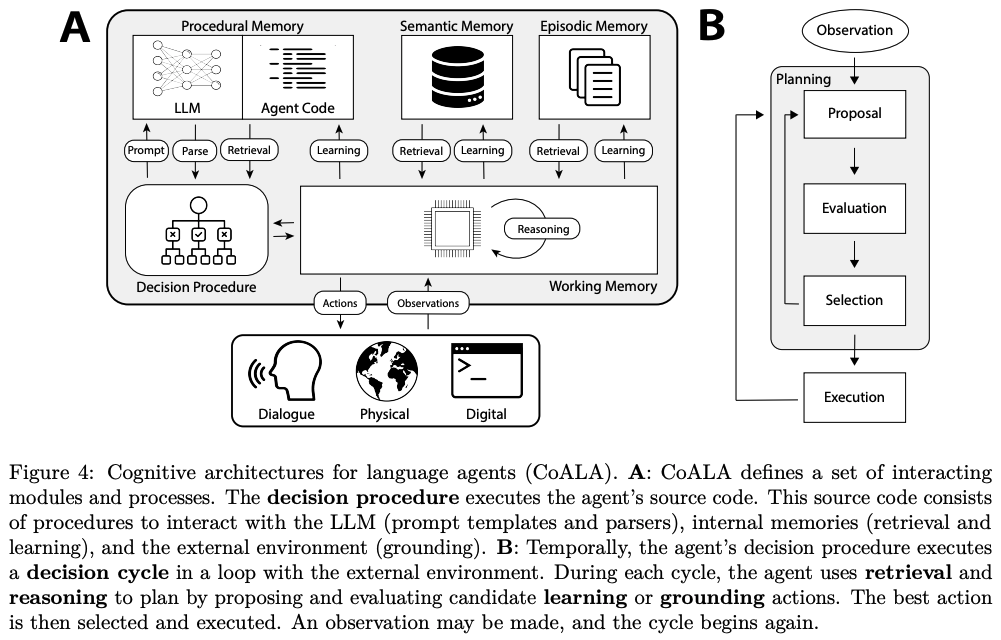
《Cognitive Architectures for Language Agents》,这篇文章在一个较高的抽象层次讨论了language agent的认知架构设计,对于理解agent的整体架构有较大的启发。其中这篇文章也是从soar的认知架构开始讲的,不过是在agent这个方向上比较早的来讲这个事情的工作。具体架构如下:
《Does AI Remember? The Role of Memory in Agentic Workflows》,这篇blog中很好的总结了agent中的memory定义。
整体上的行文思路也是类似一个考古之作,整体收获非常多。
《Dingtalk-DeepResearch: A Unified Multi-Agent Framework for Adaptive Intelligence in Enterprise Environments》,文章中提到: “Unlike static architectures, it enables agents to evolve via an entropy-guided, memory-aware online learning mechanism, retrieving high-value prior cases from an episodic memory bank and exploring diverse historical contexts.”
简单而言,在Dingtalk这个工作中,相比其他deepresearch的工作,增加了对于情景记忆的利用能力。
Memori,Open-Source Memory Engine for LLMs, AI Agents & Multi-Agent Systems,也是一个star较多的开源工作。从技术文档中可以看到,整体的实现思路和其他工业级工作是类似的。
Making Sense of Memory in AI Agents,非常全面的总结了关于memory的types以及相关的实现。这篇blog中做了一个非常有意思的类比如下(deeplearning.ai的course中也看到采用了基本相同的类比):
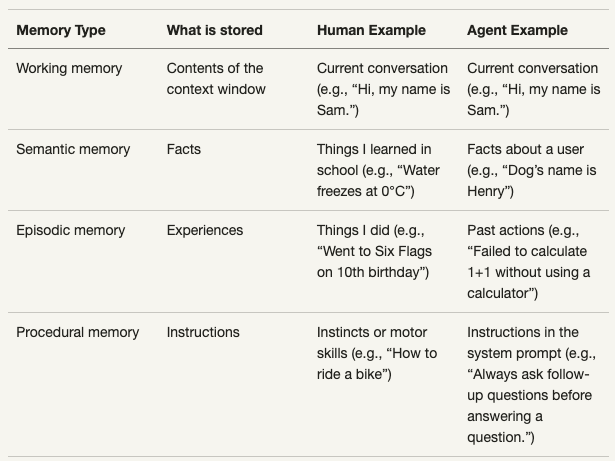
Mem0 是一个agent memory方向相对成熟度较高的公司,学术上的相关论文多次提到,《Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory》,相比其他而言,memory的架构设计也是相对清晰简单的。zep 的成熟度也相对高一些,亮点在于graph相关的memory构建,比如graphrag工作的支持等。cognee 整体上和zep比较类似。
国内的公司比如 AI 记忆革命:EverMemOS 如何让机器拥有真正的”灵魂”,github ,盛大团队关于记忆的工作,在该工作中提出了一些新的概念体系,但是技术本质上是和国外的公司是类似的。MemOS也是国内的学术团体做的一个项目,相关方向为OpenMeM。MIRIX是国外的华人学术团队做的公司(哦,这波AI热潮中,华人为主)。memu.pro 也是国内的公司,2B的业务和开源并举进行推进。
memories.ai是做视觉memory的,算是这个方向中相对较新的方向了,founder也是华人。
相关资料
-
《Evaluating Very Long-Term Conversational Memory of LLM Agents》,学术上针对长记忆能力的评测方法和评测集LOCOMO
-
Agent近期记忆技术及落地实践整理,这篇文章讨论了比较多很具体的工作,作者自身也做了较多的实践。
-
Memory Overview,LangChain中的memory机制
-
memory-template,LangChain中针对memory的具体template设计,Memory的具体使用使用方式,multi-agent之supervisor agent的实现方式,针对multi-agent,LangChain中提供了两种实现方式,分别是中心式的tool calling和去中心式的handoffs,LangMem是LangChain中的一种具体实现(面向semantic memory和episodic memory两种)
-
《Context Engineering:Sessions, Memory》,Google
-
万字解析Agent Memory实现,这篇文章中对记忆的划分提出了更多的视角,同时写作的内容和这篇blog比较类似
-
Long-Term Agentic Memory With LangGraph,DeepLearning.ai的课程,LangChain的同学主讲,有Code,LangChain官方的Code,和前边的Repo不太一样,但是基本相同
-
OpenAI Build Hour: Agent Memory Patterns 中文全文, OpenAI团队中对于Memory机制的思考
-
MindLab,国外的一家关于memory的创业公司,思路上构建了memory diffusion的方案,团队认为围绕memory,重要的不是记忆,而是遗忘。通过在size非常大的模型上进行LoRA微调,将memory注入到模型中,从而形成个性化的记忆类型。最近有感于纳排的思维逻辑应用,比如相比纳入,排除也是重要的。比如如果无法区分哪些是好的,能否区分哪些是坏的?比如记忆和遗忘的关系,比如降低成本和增加收入的trade off等。
扫码加笔者好友,茶已备好,等你来聊~